
Par Gaël Baudry, Conseiller principal, Développement et technologies
Dans mon précédent article: Le « B » de dbt ou le « T » de ETL , j’ai présenté l’outil dbt dans sa globalité, en exposant ses principales forces. Ici, il s’agira de s’attarder sur l’intérêt des certaines fonctionnalités, à savoir les snapshots et les macros dans le cadre du SCD (« Slow Change Dimension », ou encore « Dimension à évolution lente » pour illustrer sa flexibilité.
Snapshot et SCD Type 2 en DBT
En intelligence d’affaires, on parle de dimensions ou d’axes d’analyses, selon lesquels on étudie des données observables. Le SCD (« Slow Change Dimension », ou encore « Dimension à évolution lente ») correspond à la manière dont les changements dans les données sources se répercutent dans les dimensions.
Selon la stratégie employée, on souhaite ou non stocker l’historique des dimensions. Le SCD (Slow change dimension) de type 2 consiste à stocker l’historique, en indiquant des périodes de validité de chaque ligne de donnée.
Dans dbt, les « snapshot » (sortes de photos instantanées des données) sont des objets implémentant en quelque sorte le SCD de Type 2. Il s’agit d’historiser les changements, c’est-à-dire obtenir une nouvelle ligne dans la dimension à chaque fois que les données sources sont modifiées afin de garder une trace des différentes versions des données. Pour ce faire, dans dbt, on utilise la commande « dbt snapshot ». À ce moment, si les données sources ont été modifiées, le snapshot résultant va créer une nouvelle ligne pour refléter les changements, avec des champs de métadonnées particulières :
– Dbt_updated_at (timestamp de la mise à jour).
– Dbt_valid_from (timestamp correspondant au début de validité de la donnée).
– Dbt_valid_to (timestamp correspondant à la fin de validité de la donnée).
Il existe 2 stratégies permettant de définir comment une ligne est réputée avoir changé :
– Timestamp : si un champ déterminé de type timestamp a été modifié, on considère que la ligne a changé.
– Check : si un des champs parmi une liste « check_cols » a été modifié, on considère que la ligne a changé.
Ainsi, pour l’exemple suivant, dans le cas d’une stratégie « timestamp » branchée sur le champ « updated_at », si on a les données sources suivantes :
 Après exécution de la commande « dbt snapshot », le Snapshot sur cette source de données donnera :
Après exécution de la commande « dbt snapshot », le Snapshot sur cette source de données donnera :

Par la suite, si la donnée est modifiée dans les sources par :

Après exécution de la commande « dbt snapshot », le Snapshot sur cette source de données donnera :

En plus des 2 stratégies « timestamp » et « check », il est possible de créer ses propres stratégies. Pour ce faire, il suffit de créer certaines macros Jinja.
Comme la plupart des choses dans dbt, il est tout à fait possible de modifier le comportement des snapshots. En effet, en arrière-plan, dbt exécute des macros Jinja pour gérer les snapshots. Surcharger certaines macros (c’est-à-dire réécrire leur comportement par défaut) permet d’en changer le comportement.
Par exemple, au lieu d’avoir la valeur Null dans Dbt_valid_to, pour indiquer que la ligne est actuellement valide, on pourrait souhaiter avoir une valeur 9999-31-12 (une date fictive maximale). Pour ce faire, il faut surcharger les macros Jinja suivantes :
– snapshot_staging_table : création d’une table temporaire (interne à dbt dans le cadre des snapshots) contenant les éléments à ajouter/modifier/supprimer du snapshot selon les éléments contenus dans la stratégie.
– build_snapshot_table : création initiale de la table de snapshot (cas où elle n’existe pas encore au moment de l’invocation de la commande « dbt snapshot »).
– snapshot_merge_sql : constitution de l’ordre de merge à partir de la table temporaire vers le snapshot.
Illustration de la modification de la macro build_snapshot_table (pour avoir l’intégralité du code, se référer au lien github suivant).

Dans l’exemple ci-dessus, on indique la valeur des colonnes à alimenter dans le snapshot selon les valeurs issues de celles de la stratégie.
A l’étape 1 (cf. tableau plus haut), si on a utilisé la macro surchargée ci-dessus, le snapshot résultant ressemblera à ceci :

Lorsque l’on modifie ainsi le comportement des macros, il faut bien entendu veiller à tester les différents cas de figure et à s’assurer de la cohérence des résultats obtenus.
SCD hybride en DBT (snapshot + macros)
Lorsque l’on modélise des dimensions, on souhaiterait dans certains cas avoir des tables hybrides couplant SCD de type 1 avec du SCD de type 2.
Pour rappel :
– SCD type 1 consiste à ne pas historiser les changements et ne stocker que la dernière version des données.
– SCD type 2 consiste à historiser les changements et stocker toutes les informations.
Si on choisit une table en SCD type 1, il n’est pas possible d’avoir accès à des versions de données passées. En revanche, si on choisit une table en SCD type 2, on va potentiellement historiser les changements sur toutes les colonnes, ce qui crée une nouvelle ligne à chaque fois. Il n’est pas toujours pertinent de stocker tous les changements sur toutes les colonnes, ce qui pourrait dans certains contextes faire exploser la volumétrie de données. On peut donc parfois être amené à créer des tables combinant du SCD1 et du SCD2.
Pour ce faire, avec dbt, on peut se baser à la fois sur un Snapshot pour gérer la partie SCD type 2 (cf. $ précédent), et des macros pour générer la table dimension cible. Nous n’allons pas détailler ici l’aspect technique, mais le code est disponible dans le repository suivant. Voici le résultat attendu à travers des exemples.
Nous partons des éléments suivants :
– Une table source « BLOG_DBT.DBT_RAW.LISTING ».
– Un snapshot « BLOG_DBT.DBT_SNAPSHOT.LISTING » qui va nous servir de table de travail.
– Une table cible « BLOG_DBT.DBT_MDL.DIM_LISTING ».
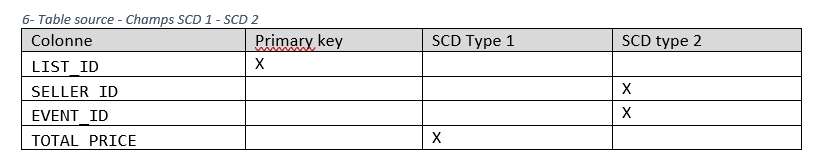
Dans la table source, nous avons plusieurs colonnes. Pour certaines d’entre elles, on va historiser les données (donc déclencher la création d’une nouvelle ligne dans le cadre du SCD type 2), et pour d’autres, on va se contenter de ne garder que la version courante.
Ceci peut être matérialisé par le tableau suivant :
Etape 1 – Données Initiales
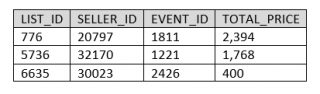
Imaginons la table source « BLOG_DBT.DBT_RAW.LISTING » contenant les données suivantes :
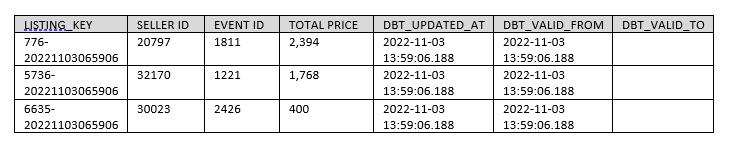
La table snapshot « BLOG_DBT.DBT_SNAPSHOT.LISTING » résultant (via l’exécution de la commande dbt snapshot -s listing) est la suivante :

Dans cette table, on a créé les éléments suivants :
– Listing_key permettant d’accéder de manière unique à une ligne de snapshot (listID concaténé avec le timestamp courant).
– Les champs préfixés DBT_ sont des métadonnées générées par DBT.
La génération de la table « BLOG_DBT.DBT_MDL.DIM_LISTING » (via la commande dbt build -s dim_listing) donne ceci :
Etape 2 – Modification d’une donnée de SCD 2
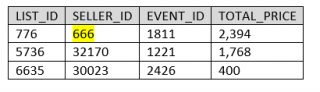
Imaginons que les données sources (table « BLOG_DBT.DBT_RAW.LISTING ») sont modifiées sur une ligne que l’on souhaite historiser (cf. tableau 6-), par exemple, « seller_id ». Les sources sont maintenant les suivantes :
La génération de la table snapshot « BLOG_DBT.DBT_SNAPSHOT.LISTING » donne ceci :
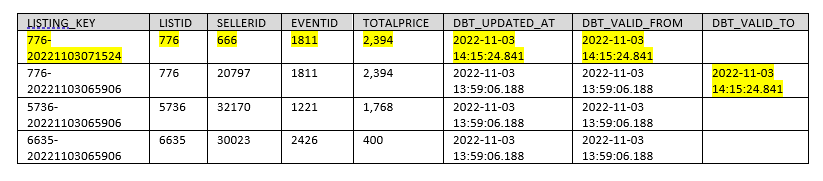
On constate qu’une nouvelle ligne a été créée dans le snapshot pour refléter l’historisation de cette modification des sources.
La génération de la table snapshot « BLOG_DBT.DBT_MDL.DIM_LISTING » donne ceci :
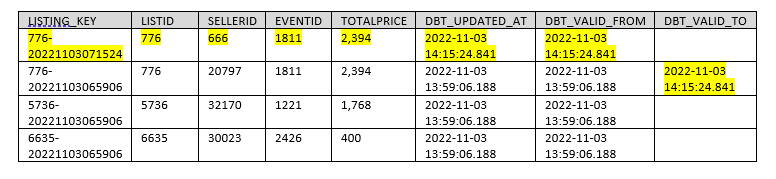
On constate que la nouvelle ligne issue du snapshot est répercutée dans la dimension.
Etape 3 – Modification d’une donnée de SCD 1
Imaginons maintenant que les données sources (table « BLOG_DBT.DBT_RAW.LISTING ») sont modifiées sur une ligne que l’on ne souhaite pas historiser (cf. tableau 6), par exemple, « total_price ».
Les sources sont maintenant les suivantes :
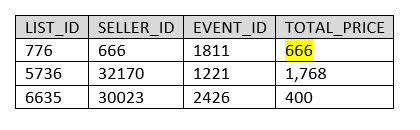
La génération de la table snapshot « BLOG_DBT.DBT_SNAPSHOT.LISTING » donne ceci :
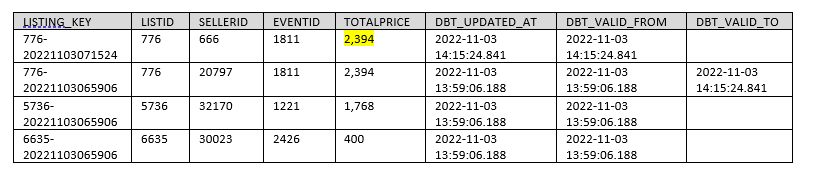
On constate que le snapshot n’a pas repéré de modification, car il n’est pas programmé pour détecter des modifications sur autre chose que « seller_id » et « event_id » (cf. tableau 6). L’utilisation seule d’un snapshot n’est donc pas suffisante dans notre cas, car on perd le changement sur le champ « total_price ».
La génération de la table snapshot « BLOG_DBT.DBT_MDL.DIM_LISTING » donne ceci :
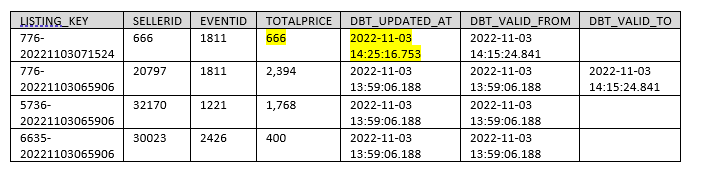
La table DIM_LISTING reflète bien les modifications sur « total_price » sans pour autant avoir généré une nouvelle ligne (SCD type 1).
On voit donc ici, qu’en jouant avec les macros dbt, on est capable de programmer certains comportements sur des tables. La puissance des macros, c’est que l’on peut généraliser un tel comportement sur plusieurs ensembles de tables, en s’appuyant sur la notion de gabarit, de manière assez simple, sans à avoir à écrire trop de code spécifique pour chaque table.
Conclusion
dbt est un outil relativement simple, mais qui peut s’avérer puissant grâce à son moteur basé sur Jinja. Les exemples évoqués dans cet article ne sont qu’une ouverture vers les possibilités offertes par l’outil. Les différents packages existants permettent de profiter du monde open source, et les macros ouvrent beaucoup de portes. Il faut cependant rester vigilent pour savoir quelle est la manière la plus adéquate pour apporter les solutions voulues. Si les possibilités sont vraiment présentes, il faut garder un équilibre entre fonctionnalités et lisibilité. Autant le code SQL reste lisible par une large audience, autant l’intégration de macros Jinja peut casser cette accessibilité. De plus, tout ne se règlera pas par DBT, la difficulté peut résider à savoir à quel niveau faire certains traitements (macros DBT, procédures Snowflake, ou autre ?).

