Par Gaël Baudry, Conseiller principal, Développement et technologies
Depuis l’avènement du cloud, le cycle ETL (Extract, Transform, Load) de synchronisation de données retourne peu à peu au cycle ELT (Extract, Load, Transform). dbt est un outil open source de transformation de données créé en 2016 au sein de RJMetrics. Cette société spécialisée dans l’analyse de données fut acquise par le groupe Magento la même année. dbt poursuivra son développement dans une firme du groupe Fishtown Analytics, pour être renommée dbt Labs en 2021.
dbt (Data Build Tool) permet aux analystes de données de travailler d’une manière proche des développeurs de logiciels. L’outil est développé en Python et est construit autour de Jinja, moteur de gabarits, très populaire dans l’univers Python. dbt est axé sur la partie Transform du cycle ELT. Son but est de simplifier la transformation de données. Dans dbt, les transformations reposent sur des modèles écrits sous forme d’instructions SQL matérialisées en tables ou en vues, ce qui les rend facilement lisibles à la fois par les analystes et les ingénieurs. dbt est convivial et ce n’est pas un hasard si plus de 16,000 organisations utilisent maintenant dbt.
Vue rapide de dbt
Il existe 2 versions de dbt : dbt Core (outil ouvert en ligne de commande) et dbt Cloud (version cloud).
dbt se repose principalement sur :
– Des instructions SQL de type SELECT.
Elles sont lisibles à la fois par des analystes et des ingénieurs. Le code SQL à lui seul établit le processus ETL. Des macros Jinja ou du code complémentaire en Python permettent de réutiliser des parties de code SQL comme gabarits.
– Des fichiers de configuration YAML .
On y définit des « sources », des « modèles » et autres fonctionnalités dbt.
Les sources de données
Les sources de données sont le point d’entrée de dbt. On définit des sources de données qui correspondent généralement à des données brutes ou à une zone de données RAW , à partir desquelles on peut définir des tables d’accueil par l’entremise de directives SQL simples.
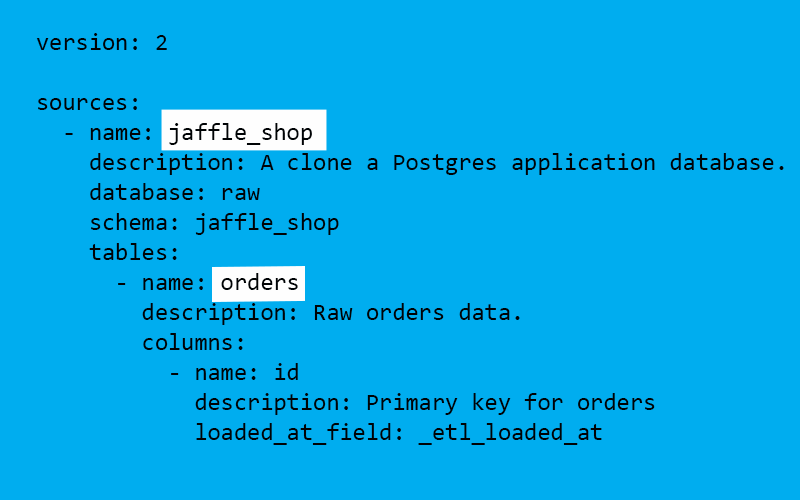
Le fichier ci-dessous est un exemple d’un fichier YAML définissant une source « jaffle_shop » et une table « orders ». Les objets ainsi définis pourront être exploités par la suite dans un gabarit SQL via le mot clé « source » (voir plus loin) :
1- fichier src_jaffle_shop.yml
Les modèles de données
Les modèles de données sont la définition et la description des objets que l’on souhaite instancier (matérialiser) sous forme de tables ou de vues. Puisque dbt produira et renseignera la matérialisation souhaitée à partir de configurations en YAML combinées à des instructions SQL, le résultat est directement couplé et ainsi très facilement modifiable.
Le fichier ci-dessous est un exemple d’un fichier YAML décrivant un modèle « stg_orders ».
2- fichier stg_jaffle_shop.yml

Grâce à cette configuration, le modèle en question pourra être utilisé par la suite dans une instruction SQL par l’entremise du mot clé « ref ».
Le modèle « stg_orders », en question est défini dans un fichier SQL. Ce fichier pourra utiliser d’autres sources et modèles ou non selon le besoin. Par exemple, le fichier SQL ci-dessous utilise la table source « orders » :
3- fichier stg_orders.sql

Ci-dessous, un autre exemple de fichier SQL utilisant cette fois le modèle « stg_orders ».
4- fichier customers_daily_summary.sql

Grâce à ses mécanismes, dbt est capable de :
- Générer un DAG (Directed Acyclic Graph).
Par la chaîne de mots clés « ref » et « source », dbt est capable de générer automatiquement le DAG. Ce diagramme permet d’assurer un ordre d’exécution (séquence d’évènements).
5- Exemple de DAG

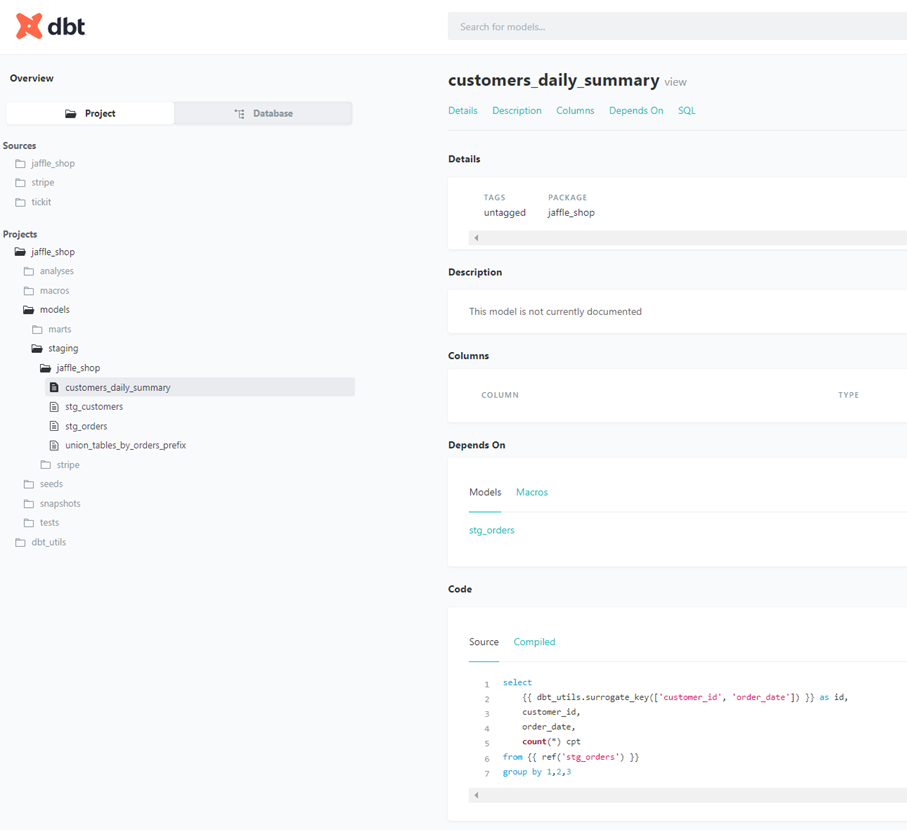
- Générer dynamiquement une documentation traçant le lignage des données. Dans l’exemple ci-dessous, la documentation affichée correspond au modèle « customers_daily_summary » défini plus tôt.
6- Exemple de documentation générée par « dbt docs generate »
- Exécuter automatiquement des tests unitaires variés (unicité, colonne obligatoire, intégrité référentielle, etc.). Pour cela, il suffit de définir certaines sections « tests » dans les fichiers de configuration YAML. Il est possible de créer ses propres tests plus avancés.
Bon à savoir : tous les tests seront présents dans la documentation.
Tous ces éléments représentent un gain de temps non négligeable sans effort supplémentaire.
Les macros dans dbt
Une des caractéristiques importantes de dbt est qu’il repose sur le moteur de gabarits Jinja.
Ce dernier permet entre autres de :
- Utiliser des structures de contrôle (if, boucles…)
- Utiliser des variables d’environnement
- Avoir des comportements réutilisables sur plusieurs objets (tables, vues)
- Rendre paramétrables des noms de schémas.
Ainsi, une certaine logique programmatique peut être ajoutée et être employée dans l’élaboration de modèles complexes.
De plus, certaines macros, définies par défaut dans dbt, peuvent néanmoins être modifiées pour changer le comportement de certains éléments. Nous détaillerons ceci dans une seconde partie de ce billet sur notre blogue.
D’autres arguments en faveur de dbt?
Il y en a plusieurs:
- Orchestration: dbt peut orchestrer lui-même le rafraîchissement des données (jobs : https://docs.getdbt.com/docs/get-started/getting-started/building-your-first-project/schedule-a-job), ou être intégré par exemple dans un pipeline Azure DevOps.
- Contrôle de version: dbt est obligatoirement intégré avec git, imposant ainsi le contrôle des versions du code.
- Modularité: Les gabarits Jinja sont facilement réutilisables et de nombreux packages sont disponibles librement, en particulier sur le site : https://hub.getdbt.com/
Conclusion
Pour résumer, dbt est un outil convivial, relativement simple, mais puissant. Il facilite les transformations du cycle ELT et prend automatiquement en charge la documentation, le lignage des données et les tests. Sa philosophie DevOps constitue une vraie force. dbt est très extensible et les macros Jinja ainsi que les différents packages existants permettent de profiter du monde open source et ouvrent beaucoup de portes.
Dans une 2e partie de cet article, nous irons plus loin dans certaines applications qui découlent de l’utilisation des macros dans des exemples concrets.




