
Par Alexandre Lepage, Directeur principal, Entreprise numérique
Hub, lac, voûte, entrepôt, comptoir, cube de données… Et une souris verte. Pourquoi faire simple quand on peut faire compliqué?
Je conçois et développe des solutions orientées données depuis maintenant 25 ans (d’où la souris verte…) et ne peux cacher un sourire en coin chaque fois qu’on annonce une nouvelle révolution, plus souvent terminologique qu’épistémologique, dans le merveilleux monde de la gestion et de la valorisation des données.
Et les choses ne s’améliorent pas lorsqu’on s’intéresse à l’architecture d’une plateforme de données et qu’on explore les zones dans lesquelles les données transiteront, de leurs sources jusqu’à leur consommation. Faites l’essai : tapez data zones dans votre moteur de recherche préféré et dites-moi, ces zones, combien sont-elles? Comment se nomment-elles?
Depuis quelques années déjà, j’y vais de mes propres définitions et je me suis dit : pourquoi ne pas les partager, ne serait-ce que pour contribuer volontairement à la confusion générale?
Mes cinq zones de données
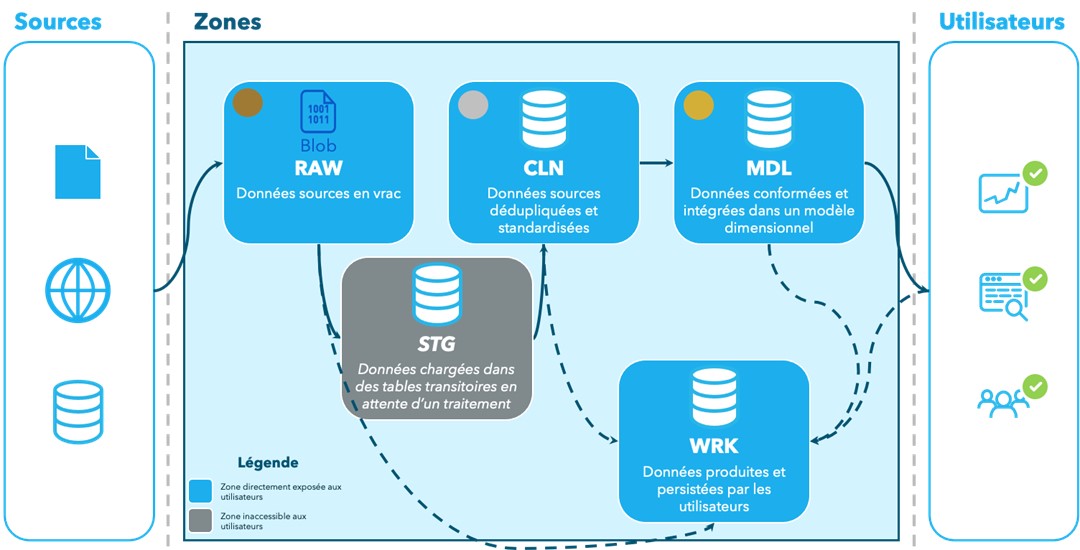
Que ce soit pour une plateforme de données centralisée ou pour une solution plus distribuée (à ce propos, même un dinosaure comme moi reconnaît beaucoup de bon dans le maillage de données introduit par Zhamak Dehghani dans son article de 2019 : hélas, la réingénierie organisationnelle requise pour le mettre en place ne me semble pas des plus triviales), j’aime bien répartir les données en cinq zones aux responsabilités et caractéristiques bien distinctes :
RAW
Le rôle la zone RAW est simple : stockage et archivage des données sources en vrac, dans un format le plus natif possible, et exposition éventuelle à une consommation exploratoire ou spécialisée, en particulier pour des données qui ne seraient pas acheminées vers les autres zones en aval.
Comme le diagramme précédent le suggère, je préfère que cette zone soit hébergée dans le cloud à l’aide de ressources de stockage automatiquement extensibles et bon marché (Azure Blob Storage, Amazon S3, Google Cloud Storage), mais, selon la stratégie d’acquisition, par exemple une stratégie de réplication, une base de données de nature relationnelle peut très bien faire l’affaire.
STG
La zone STG, ou de staging, est une zone de travail, inaccessible aux utilisateurs et qui n’existe qu’afin de faciliter les processus subséquents. Et puisqu’il s’agit de préparer la suite en « chargeant » des données en attente d’un traitement, je choisis encore à ce jour une base de données de nature relationnelle pour supporter cette zone.
Les données ne sont pas persistées à long terme dans la zone STG (n’en déplaise aux fans, persistent staging area est un oxymore). Mieux, cette zone, comme les autres d’ailleurs, n’est en aucun cas obligatoire.
CLN
D’aucuns la nomment curated zone, trusted zone ou encore silver zone mais moi, j’emploie cleaned zone, ou zone CLN. À nomenclature près, cette zone joue un rôle charnière dans une plateforme de données : stockage et exposition de données sources dédupliquées et dans un format standardisé (dates, nombres, etc.).
Les utilisateurs qui puisent des données de cette zone sont assurés que celles-là sont « de qualité » même si elles ne répondent peut-être pas directement à un besoin d’analyse spécifique. Si je peux me permettre une analogie avec la culture du sucre, et si on considère les données de la zone RAW comme des cannes récoltées, les données de la zone CLN sont du sucre raffiné : c’est plus proche que ce que l’on souhaite en général, mais, à moins qu’on soit glouton, on n’a toujours pas un dessert.
Ici aussi, j’opte pour un support relationnel, surtout si les données sont versionnées. Et comme modéliser est un effort d’abstraction qui n’est jamais trivial, je ne modélise pas, et donc ne transforme pas (ou si peu), les données dans la zone CLN. Toutefois je les y conserve à vie (ou jusqu’à la retraite).
MDL
La zone MDL, ou modeled (duh!), est celle qui supporte le plus directement l’analyse récurrente. Parce qu’elle contient des données conformées et intégrées dans un modèle approprié, cette zone constitue une source privilégiée pour la consommation de données.
On commence à me voir venir : oui, encore une fois, je privilégie une base de données relationnelle pour stocker les données de la zone MDL. Bagage oblige, je favorise encore le bon vieux modèle dimensionnel : il répond très bien à beaucoup de cas d’usage. En support à l’apprentissage machine, un référentiel de caractéristiques ne m’embêterait pas non plus : je parlais de dessert plus tôt, dans mon analogie avec la culture de la canne à sucre, mais certains ont plus soif de rhum!
WRK
La dernière zone est la zone WRK, ou de travail, dans laquelle les utilisateurs manipuleront et conserveront les données qu’ils produisent et/ou qui ne passent pas par un certain cycle industrialisé. Oui, cette zone constitue le carré de sable (ou cage de Faraday?) permettant aux analystes de sauvegarder des données nécessaires à leurs travaux ou qui en résultent.
Le diagramme en début de section suggère l’emploi d’une technologie de nature relationnelle pour supporter la zone WRK, ce qui est souvent le cas dans mes plateformes de données, mais, bien franchement, les bonnes technologies à utiliser sont… celles qui font l’affaire?
Conclusion
Je trouve que mon découpage en cinq zones de données aide beaucoup à la réflexion lorsqu’on commence la réalisation d’une plateforme de données. Il facilite les choix des infrastructures et technologies qu’on aura à faire tant pour les zones elles-mêmes que pour les transitions entre elles. Il contribue également à encadrer les discussions sur plusieurs autres aspects importants d’une plateforme analytique : approvisionnement, ordonnancement, sécurité, gestion des métadonnées, gestion de la qualité des données, politiques et gouvernance.
Et ces cinq zones s’inscrivent bien dans les principaux composants attendus d’une plateforme de données moderne comme un lac ou un entrepôt de données. À titre d’exemple (bah oui! j’illustre explicitement Snowflake, mon jouet des quelques dernières années, dans le diagramme : sue me!) :
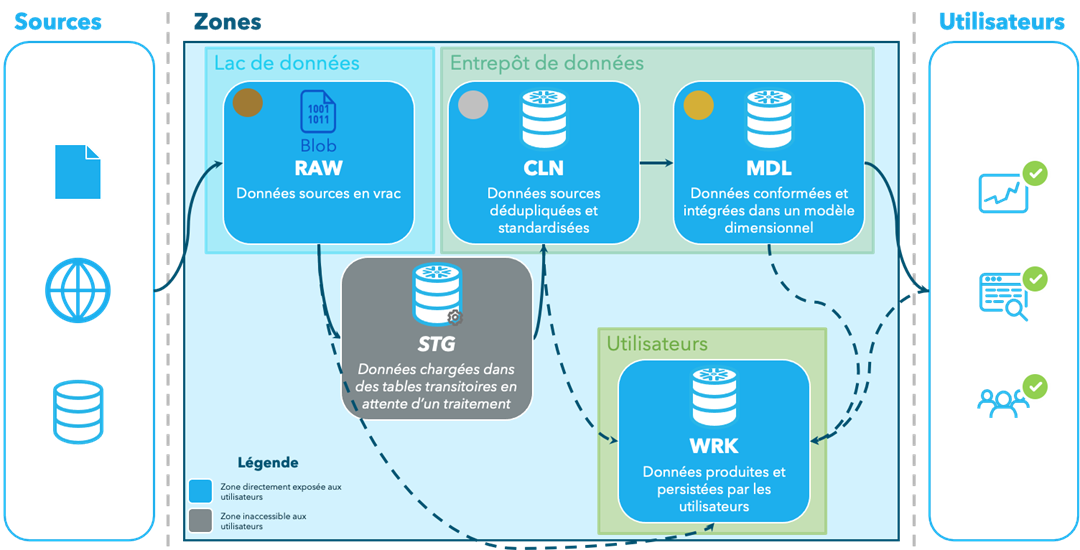
Plusieurs trouveront peut-être que mon découpage en zones est simpliste. Comme je le disais au tout début : pourquoi faire compliqué quand on peut faire simple?



