
Par Charles Saulnier, Directeur, Analytique des données
Les milieux de l’analytique et de l’intelligence augmentée sont au cœur des discussions et de notre quotidien, parfois plus que nous ne le réalisons. En tant que professionnels de ces domaines, nous sommes bien au fait de l’impact que certaines technologies promettent d’avoir sur notre pratique, tout autant que des (fortes) chances que la réalité ne soit pas au niveau de ces promesses…
J’ai récemment eu la chance de me pencher plus sérieusement sur une des technologies qui a le potentiel d’ajouter une valeur notable au travail des équipes de science de données : la génération de données synthétiques. Vous trouverez dans les prochains paragraphes une définition de ces données, les contextes d’utilisation les plus courants, un survol de quelques fournisseurs en vue dans ce marché et notre perspective sur la valeur que ces données peuvent apporter aux entreprises.
Que sont les données synthétiques?
(1) Definition of Synthetic Data – Gartner Information Technology Glossary
Le processus de génération de données synthétiques peut varier selon l’objectif, mais ressemble habituellement à ceci :
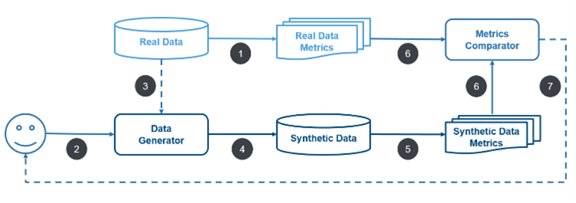
(1) Compilation des propriétés statistiques des données réelles.
(2) Le produit ou un scientifique de données développe un générateur (par des méthodes statistiques ou une simulation).
(3) Le générateur est raffiné à partir des données réelles.
(4) Exécution du générateur afin de créer les données synthétiques.
(5) Compilation des propriétés statistiques pour les données synthétiques.
(6) Comparaison des propriétés des données réelles et synthétiques.
(7) Cycle d’évolution du générateur pour que les propriétés des données synthétiques continuent de s’améliorer.
Quels sont les contextes d’utilisation des données synthétiques?
Deux scénarios sont fréquemment cités dans la littérature :
– L’accélération des opérations de type MLOps (mise en production de modèles IA pour répondre à un besoin d’affaires).
– La génération sur demande de données de test.
Le scénario MLOps semble celui où les fournisseurs sont les plus actifs, et présente plusieurs cas d’utilisation plus concrets :
- En finance : la détection de fraude est le cas le plus cité. Les données synthétiques permettent alors de simuler des événements de fraude qui sont une infime partie des transactions réelles disponibles.
- En télécommunication : la détection d’anomalies et prévention de pannes sont des cas d’application prometteurs.
- En santé : la génération de données peut permettre de compenser les déséquilibres démographiques dans les échantillons liés à des maladies rares.
- Pour les commerces de détail : les systèmes de recommandation et de prévention de l’attrition sont des éléments faisant souvent la différence entre une entreprise prospère, capable d’innover, et une en difficulté.
Illustrons un cas d’utilisation fréquemment cité par les éditeurs, soit la détection de fraude dans le domaine financier. Voici une illustration du processus de déploiement et d’utilisation du modèle habituel à haut niveau :
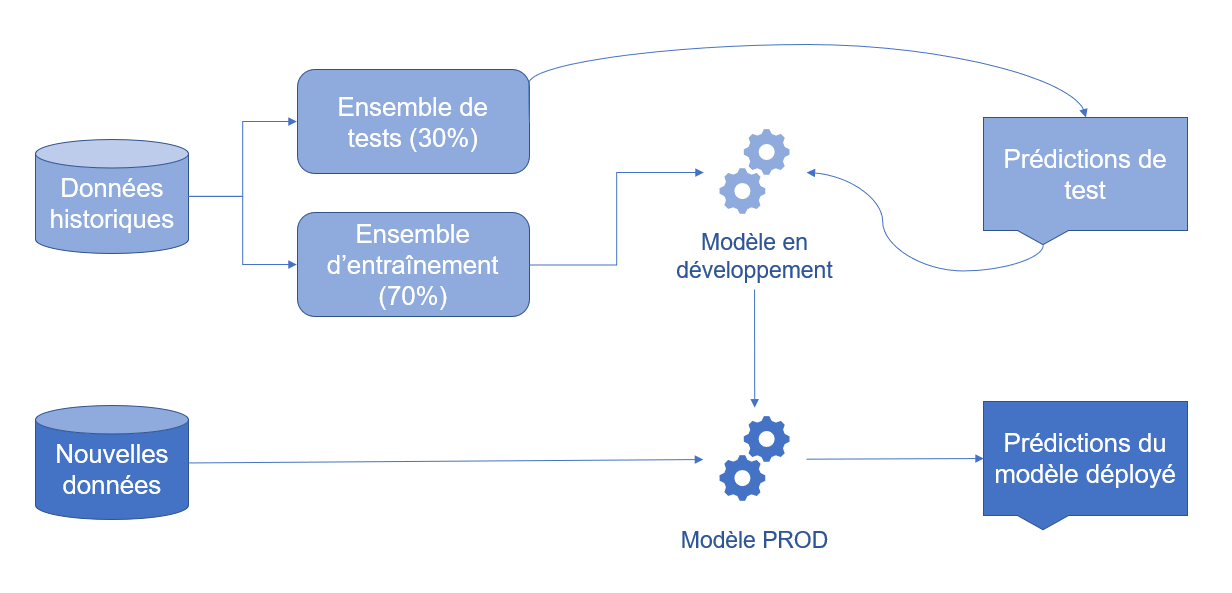
Selon Mint, 459 297 transactions de carte de crédit frauduleuses aux États-Unis en 2020 furent déclarées. Cela peut sembler énorme !! Mais lorsque l’on tient compte du fait que plus de 39,6 milliards de transactions par carte de crédit ont été enregistrées dans ce même pays en 2019 (posons l’hypothèse que le nombre de transactions a été similaire en 2020 malgré la pandémie), cela ne représente que 0,001% des transactions. Il est donc fort possible qu’un échantillon de données réelles ne contienne que peu ou pas de transactions frauduleuses. Difficile alors d’identifier des éléments permettant d’améliorer ou de mettre à l’épreuve notre système de détection de la fraude… Dans le diagramme ci-dessus, comme les données réelles sont subdivisées pour générer les ensembles de tests et d’entraînement, les comparaisons se font sur un nombre de cas frisant le 0…
Comment les données synthétiques peuvent-elles alors nous aider? Elles présentent deux opportunités aux scientifiques de données :
- Les données réelles / de production étant hautement sensibles, il est souvent fastidieux d’avoir accès à un ensemble de données significatif pour développer ou optimiser un algorithme. Les données synthétiques ne présentent pas un tel enjeu de données personnelles, et peuvent ainsi réduire le délai entre les itérations d’un modèle;
- De par la capacité de génération de données à la demande, il est possible de multiplier les cas et donc d’offrir plus de données d’entraînement au modèle. Cela permet à celui-ci d’offrir une précision accrue comparativement à un modèle entraîné uniquement à partir de données historiques.
Si l’on reprend l’illustration ci-haut, les données synthétiques peuvent équilibrer le nombre de cas positifs de fraude dans notre ensemble d’entraînement, et donc au final donner un modèle plus précis et sensible :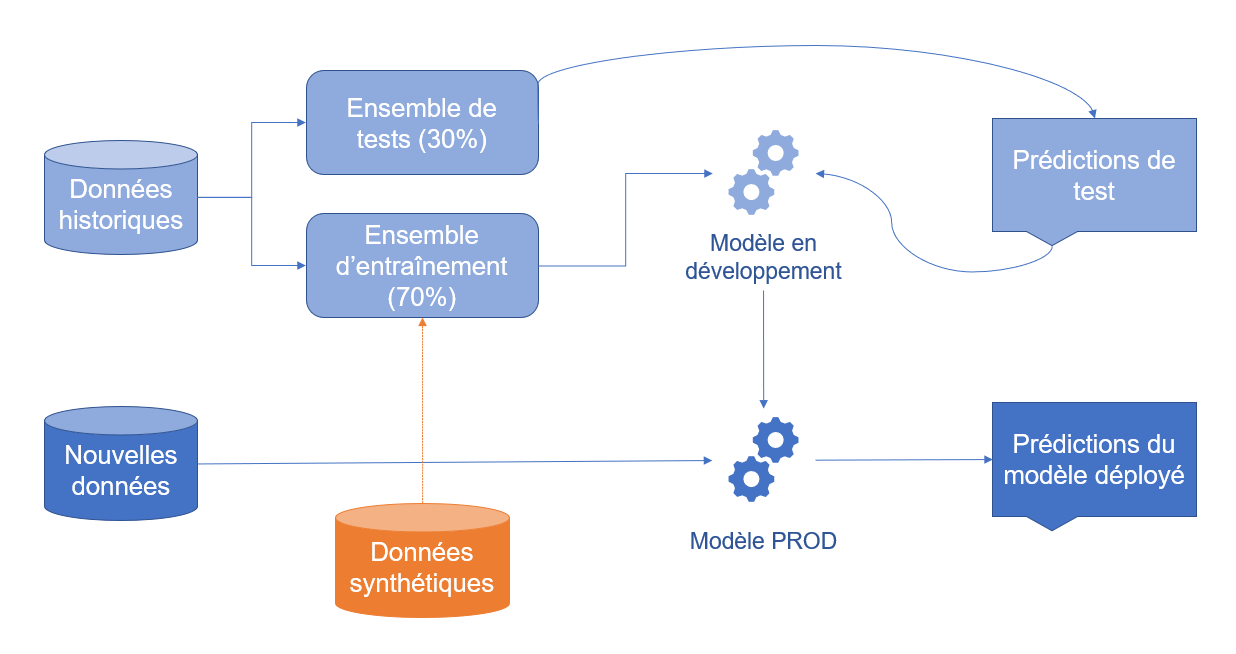
Ce principe peut s’appliquer en théorie à des cas d’utilisation dans l’ensemble des domaines ci-dessus et bien d’autres. Cela explique la prévision de Gartner qui affirme que d’ici 2024, 60 % des données utilisées pour le développement de projets analytiques et d’intelligence artificielle seront synthétiques.
En ce qui concerne les éditeurs, un nombre impressionnant d’entreprises se sont lancées dans le marché des données synthétiques au cours des 5 dernières années. AIMultiple recensait 19 éditeurs au début 2022. Le sujet étant nouveau pour nous aussi, nous n’avons pu faire une analyse approfondie de l’ensemble des éditeurs. Soulignons toutefois les entreprises suivantes avec lesquelles nous avons à tout le moins eu une démonstration des produits :
Hazy, entreprise britannique spécialisée dans les cas d’utilisation en finance.
Tonic.AI, se démarquant par l’éventail de types de données supportés et la flexibilité des générateurs.
Nous terminons ce survol avec Ydata, entreprise portugaise finaliste de Techstars Montreal AI 2020 proposant une solution compatible avec les 3 principaux fournisseurs cloud.
Nous avons eu la chance d’utiliser leur plateforme durant quelques semaines et d’explorer leur offre. Cette dernière se décline en 4 composantes :
- Data Sources, où les connexions de données sont générées et le profil de qualité de données est disponible.
- Labs, des espaces de travail (par exemple des carnets JupyterLab) pour définir les étapes de l’analyse à effectuer, dans notre cas un ensemble de scripts Python pour effectuer nos tâches.
- Synthesizers, qui permet de générer des données synthétiques à partir des sources de données existantes.
- Pipelines, qui peuvent se rattacher à d’autres applications pour, par exemple, fournir un jeu de données synthétiques généré à partir d’un Lab à une application de simulation ou de tests.
Écran d’accueil YData
Tous ces modules sont hébergés dans un espace de travail (personnel ou d’équipe) au sein duquel différentes permissions peuvent être attribuées.
Le module Synthesizer est vu comme un produit dédié permettant de générer des données synthétiques à partir des données d’origine, sans transformation ni copie des données originales. Il n’est pas nécessaire de définir un ou des Synthesizer pour générer des données synthétiques dans un Lab; ce module permet par contre de rapidement générer des jeux de données synthétiques et d’en évaluer les propriétés statistiques à la volée.
Quelques écrans de l’interface graphique YData:
Écran de connexion aux données
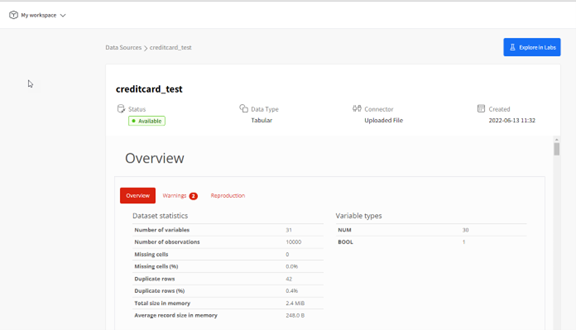
Analyse initiale des données source
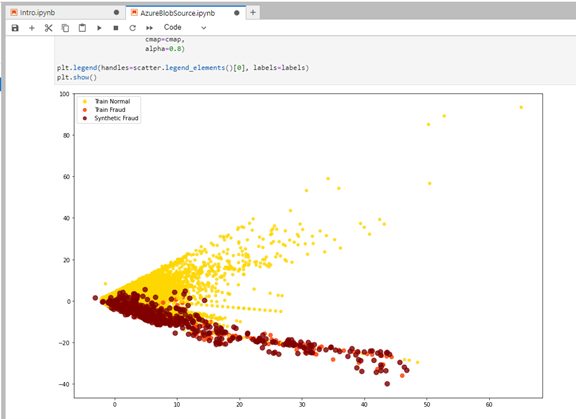
Exemple de Lab dans Jupyter
Références en vrac:
https://mostly.ai/blog/15-synthetic-data-use-cases-in-banking/