
Par Alexandre Lepage, Directeur principal, Entreprise numérique
Le contexte
Larochelle est une firme services-conseils en technologie de l’information présente à Montréal et à Québec. Elle regroupe 175 talents permanents et collaborateurs spécialisés en Analytique des données, Conseil en gestion et Développement et technologies.
Larochelle, comme bien des entreprises au Québec, fait face à un plein emploi de plus en plus concret; le dynamisme indéniable des recherchistes et recruteuses de son équipe Attraction de talents et une participation très active dans diverses missions de recrutement internationales ne suffiront peut-être plus à supporter la croissance organique espérée !
Grossir les rangs de l’Attraction de talents demeure toujours une option mais présente les mêmes défis que recruter un candidat pour les services-conseils. Pouvons-nous envisager d’autres options? Par exemple, pouvons-nous innover et gagner en efficacité en dotant les recherchistes et recruteuses d’outils et d’informations leur permettant de cibler les candidats à haut potentiel d’employabilité ?
Pour une firme québécoise spécialisée en particulier en analytique des données, quoi de plus naturel, en 2019, de considérer l’apprentissage machine comme piste de solutions : l’intelligence artificielle à la rescousse de l’attraction de talents !
Plus précisément, sachant que Larochelle cumule, dans son système de gestion des postulants, une pléiade de données sur près de 20,000 candidats, certains ayant été embauchés, la plupart non, pouvons-nous considérer l’usage d’un ou plusieurs algorithmes afin de produire un modèle prédictif quant à l’employabilité d’un candidat donné ?
Eh bien, c’est là la question que nous avons posée à une équipe composée de 4 étudiants de 3ème année du baccalauréat aux HEC de Montréal comme projet de session dans le cadre du cours Projet intégrateur en intelligence d’affaires.
La réponse ?
La démarche
Accompagnés de bibi qui agissait occasionnellement à titre de conseiller scientifique et technologique, de Julie Pelland, conseillère au recrutement qui jouait le rôle d’experte de domaine, et de Marie-José Lesage, vice-présidente responsable du centre d’excellence Conseil en gestion qui relançait tout ce beau monde, les étudiants avaient quelques semaines, pour :
- Profiler le contenu – anonymisé bien entendu, pour les esprits inquisiteurs catastrophés à l’idée d’une divulgation éventuelle d’informations privilégiées – de la base de données MySQL supportant notre système de gestion des postulants – CATS, ou Applicant Tracking System, pour les mêmes esprits;
- Identifier, préparer et nettoyer les données jugées pertinentes au modèle à définir;
- Sélectionner un ou des algorithmes d’apprentissage machine adaptés au problème et, selon le ou les choix, potentiellement retravailler les données identifiées;
- Évaluer le modèle et, lors du dernier cours le 8 avril dernier, présenter résultats et éventuelles recommandations à Annie Loiselle, vice-présidente responsable de l’Attraction de talents.
Clair ?
Le problème
Transposé en un problème d’apprentissage machine supervisé et traduit dans son langage propre, la question posée à nos 4 étudiants s’exprime comme suit :
- Considérant l’étiquette représentant l’employabilité d’un candidat: afin de simplifier un peu les choses, y, le résultat de la prédiction, est une variable booléenne qui vaut 1 si le candidat est employable, 0 sinon; selon les données contenues dans notre système de gestion des postulants un candidat employable est un (ex-)candidat qui est ou a déjà été à l’emploi de Larochelle;
- et selon les caractéristiques {x1, x2, …, xn} d’un candidat : ces caractéristiques, comme le degré de scolarité, le niveau de maîtrise du français, des aptitudes dans un langage de programmation donné, la connaissance d’une certaine méthodologie, etc., sont les variables en entrée combinées pour prédire l’employabilité du candidat;
- est-il possible d’entraîner un modèle à l’aide de suffisamment d’exemples étiquetés : sachant que des exemples étiquetés sont des exemples pour lesquels et les caractéristiques {x1, x2, …, xn} et l’étiquette sont connues, entraîner un modèle consiste donc à identifier une relation entre caractéristiques et étiquette à partir de ces exemples;
- et l’appliquer à des exemples non étiquetés pour inférer l’étiquette : dit autrement, l’utiliser pour prédire l’employabilité de futurs candidats ?
Simple ?
La réalité
Sachant que les étudiants ne pouvaient puiser que dans la base de données MySQL supportant CATS, et en supposant que cette source unique était suffisante pour proposer éventuellement un modèle prédictif, les premières questions – questions fondamentales – qu’ils se sont posées étaient :
- Pouvons-nous identifier dans la base de données des caractéristiques {x1, x2, …, xn} qui peuvent être combinées de manière plausible pour prédire l’étiquette ? En sous-texte : connaissons-nous suffisamment le domaine d’affaires – les services-conseils en technologie de l’information – pour y aller d’un choix éclairé? Par exemple, même s’il était possible de trouver une relation entre le numéro d’identification d’un candidat et son employabilité – ce l’est – ce ne serait pas particulièrement pertinent et, surtout, que pourrait faire une recherchiste ou une recruteuse d’un tel modèle ?
- Les caractéristiques sélectionnées sont-elles directement contenues dans les quelque 560 colonnes réparties dans près de 60 tables de la base de données ou doivent-elles être dérivées d’une quelconque manière? C’est classique, les bonnes caractéristiques ne sautent pas toujours aux yeux et, sans même parler des besoins algorithmiques à venir, manipulation et enrichissement de données sont à prévoir. Nagerions-nous dans le T de ETL ici ?
- Quelle est la qualité des données supportant une caractéristique choisie? Poser cette question, c’est un peu passer du côté obscur de la Force et révéler ce que d’aucuns savent et peu admettent : les marchands du temple sont prompts à nous rappeler que les données sont le pétrole du 21e siècle, mais il y a pétrole, il y a sable bitumineux et, bien souvent, il n’y a que fange …
Nos joyeux lurons ont donc d’abord profilé les données et… galéré. Eh oui :
- Nos pauvres recherchistes et recruteuses travaillent avec une très vieille version de CATS qui expose trop souvent des champs textes libres plutôt que des listes défilantes : les étudiants nous ont d’ailleurs recommandé d’y voir !
- Elles saisissent beaucoup d’information par l’entremise de champs commentaires, de listes concaténées et de notes difficiles à exploiter;
- Elles n’obtiennent pas toujours toute l’information requise et beaucoup de champs, nécessairement optionnels, sont laissés vides : par exemple, même une caractéristique potentielle comme le niveau de maîtrise du français n’est renseignée qu’à 30%.
Il existe toutes sortes de techniques relativement usuelles comme l’extraction de termes, le « dummy coding », la substitution, l’interpolation, etc. pour pallier à quelques-uns de ces problèmes, mais je crois que notre équipe demeure encore à ce jour surprise d’avoir eu à consacrer une telle proportion de temps et d’énergie à préparer les données pour les rendre exploitables. Je ne le suis pas.
L’êtes-vous ?
Les algorithmes
Afin de produire ensuite le modèle prédictif attendu, les étudiants ont employé le logiciel SAS Enterprise Miner pour entraîner et évaluer 4 modèles basés sur les algorithmes suivants :
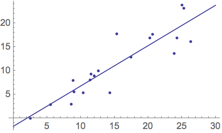
- La régression linéaire : approche statistique qui consiste à postuler que la relation entre caractéristiques {x1, x2, …, xn} et étiquette est linéaire et à trouver l’équation linéaire – une droite s’il n’y a qu’une seule caractéristique, un plan s’il y en a deux, un hyperplan s’il y en a plusieurs – qui approxime le mieux cette relation;
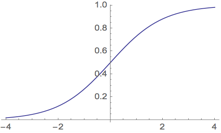
- La régression logistique : approche statistique qui consiste à postuler que la relation entre caractéristiques {x1, x2, …, xn} et étiquette est logistique et à trouver l’équation de la fonction logistique – en deux dimensions, une sorte de courbe en forme de S – qui approxime le mieux cette relation;
- La régression parcimonieuse LAR ou Least Angle Regression : sorte de variante sophistiquée de la régression linéaire qui permet en quelque sorte d’identifier à la fois un sous-ensemble dans les caractéristiques {x1, x2, …, xn} et l’équation linéaire qui approxime le mieux la relation entre ce sous-ensemble et l’étiquette;
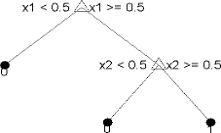
- L’arbre de décision : approche symboliste qui consiste à identifier dans les caractéristiques {x1, x2, …, xn} une série de règles logiques « if… then… else… » successives qui déterminent probablement l’étiquette y.
J’ai volontairement simplifié les définitions ci-dessus : que les esprits inquisiteurs de tout à l’heure qui s’en offusqueraient m’épargnent leurs doléances.
Toujours simple ?
Les résultats
Nos étudiants ont fait des choix d’algorithmes plutôt convenus, mais a priori légitimes dans le contexte du projet : après tout, nous ne leur demandions pas ici d’améliorer le système de recommandations de Netflix! Ils ont donc entraîné puis évalué les 4 modèles et algorithmes sélectionnés pour conclure qu’un modèle de type régression logistique – statistiques, évaluation des coefficients, etc. à l’appui, mais pas de matrice de confusion – prédisait l’employabilité de candidats non étiquetés avec la meilleure précision.
Je ne détaillerai pas dans cet article les diverses évaluations et n’entrerai pas dans les détails des caractéristiques {x1, x2, …, xn} considérées et les coefficients correspondants, non pas que ce ne soit pas intéressant en soi, mais je m’en voudrais d’étaler ainsi sur la voie publique une certaine proposition de modèle quant à l’employabilité de candidats : c’est un marché d’employés, pas d’employeurs, et la compétition est féroce !
Et maintenant ?
La suite
Larochelle ne déploiera pas le modèle proposé par les 4 étudiants des HEC et le faire aurait été étonnant, ne serait-ce que parce que quelques caractéristiques choisies par ceux-là sont peu raisonnables compte tenu de notre expertise et de notre marché. Et ce n’est pas ici un désaveu du travail effectué par notre équipe d’étudiants dans le cadre de ce projet ambitieux, bien au contraire : ils ont fait du bon boulot et je les en félicite.
Ils ont également appris une leçon essentielle : le terme « apprentissage » dans apprentissage machine n’est que la pointe de l’iceberg, le « teaser » publicitaire, la cerise sur le sundae, le repos du guerrier, et le gros du travail demeure et demeurera pour un bon moment encore la tâche ingrate de collecter, profiler, sélectionner, organiser, nettoyer et préparer les données. Tiens donc.
Mais maintenant que nos étudiants ont sué sang et eau à rendre exploitables les données sur nos candidats et qu’ils m’ont remis le fruit de leurs efforts sous la forme d’un beau jeu de données tout propre, je compte bien en profiter! J’annonce ici-même dans cet article, en grande fanfare, que Larochelle lancera sous peu un concours ouvert à tous ses talents et qui récompensera les personnes ou équipes qui proposeront le meilleur modèle prédisant l’employabilité de candidats à partir de ce jeu de données : les détails de cette compétition Kaggle maison seront communiqués par la canaux habituels et les résultats – peut-être pas, si trop prometteurs – feront certainement l’objet d’un article futur.
Relèverez-vous le défi ?
